
数据分析能力养成指南16:数据分析必须懂的假设检验

本文是《如何七周成为数据分析师》的第十六篇教程,如果想要了解写作初衷,可以先行阅读七周指南。温馨提示:如果您已经熟悉概率分布,大可不必再看这篇文章,或只挑选部分。
在前一篇讲完概率分布后,我们再接再厉拿下假设检验,也就是大名鼎鼎的AB Testing。俗话说得好,再优秀的产品经理也跑不过一半AB测试。
抽样
数据分析中,虽然数据越多越齐越好,可是受限于各类因素的制约,我们并不能获取全部的数据。比如Excel的性能限制,比如数据库不支持大文件导出、或者是无法全量进行的用户调研等。
抽样是一种应对方法,通过样本来推断总体,抽样结果提供的仅仅是相应总体特征的估计,「估计」这一点很重要。
抽样有很多方式,样本首要满足随机性。比如进行社会访谈,你不能只选择商场人流区,因为采访到的人群明显是同一类人群,反而会遗漏郊区和乡镇的人群,遗漏宅男,遗漏老人。
互联网产品中,抽样也无处不在,大名鼎鼎的AB测试就是一种抽样,选取一部分人群验证运营策略或者产品改进。通常筛选用户ID末尾的数字,比如末尾选择0~4,于是抽样出了50%的用户,这既能保证随机性,也能保证控制性。
毕竟抽样的目的是验证和检验,需要始终保证用户群体的完全隔离,不能用户一会看到老界面,一会看到改进后的新界面。以上也适用于推荐算法的冠军挑战,用户分群等。
至于放回抽样,分层抽样,在互联网的数据分析中用不太到,这里就略过了。
点估计
既然我们已经知道如何选择一个样本,接下来需要从样本推断总体。
列举一个场景。产品和运营人员每周都会进行一次用户调研,调研随机抽取30位用户对产品进行打分,分数0~10。根据历史数据计算出平均7.5分,标准差为1分。
现在的问题是,用户调研能否反应一些产品的状况?比如发布新版本,或者做了营销活动后,怎么判断是正面影响还是负面?假设本月产品经理们发布了一次新版本,这次调研抽取30位用户平均评分是7.3,究竟是正常的波动还是做糟糕了?
在统计学中,把总体的平均值标准差等称为总体参数,把样本的种种指标称为点估计量。s是样本标准差,σ是总体标准差。n是样本,N是总体。
点估计在原有的符号上加横线表示,比如样本均值![]() x拔是样本均值,现实中不可能保证每次调研的数据都是一致的,假设将抽样过程一而再,再而三的进行下去,那么调研获得的平均分也是波动的。此时,样本均值x拔是一个随机变量,称它的概率分布为x拔的抽样分布。
x拔是样本均值,现实中不可能保证每次调研的数据都是一致的,假设将抽样过程一而再,再而三的进行下去,那么调研获得的平均分也是波动的。此时,样本均值x拔是一个随机变量,称它的概率分布为x拔的抽样分布。
每次抽样得出的不同均值,必然会有一个期望值,E(x拔) = u,E(x拔)就是所有大量抽样的可能值的均值。对简单随机抽样,我们可以认为其数学期望等于u总体均值。当点估计量的期望值等于总体参数时,称为无偏估计。
当样本量占总体5%以上时,有求样本标准差公式如下:

当样本量占总体5%以下时,公式可以简化成:
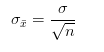
研的用户量肯定小于总体5%,于是能求出样本的标准差为0.18。
上述数学期望和标准差的计算适用于所有总体,可如果想要知道具体的概率呢?比如分数小于等于7.3的可能性?如果是10%,那么说明这是稀少的情况,产品的改版未必尽如人意。如果是90%,说明这是数据的正常波动。
x拔作为概率分布,也非为正态分布和非正态分布。根据统计学中的中心极限定理,当样本数足够时(n>30),x拔的抽样分布可近似于正态分布。
只要是正态分布就好办了,把问题转换成标准正态分布的概率求解。调研样本评分x=7.3分,标准差σ为0.18。总体均值u为7.5分。
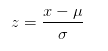
z = (7.3-7.5)/0.18 = -1.11。于是P(x<=7.3)=P(z<=-1.1) = 13.3%。上述结果说明,本次抽样得到7.3分(或者更低)的概率为13.3%,产品人员或许可以相信,这次改版并不好。
通过抽样估算总体,它的概率计算是以样本标准差作为依据的,换言之,如果样本标准差变化,则概率一定变化。而样本标准差和样本容量n息息相关。如果调研用户数是100位,那么哪怕其他数字没变化,最终概率也会变成2.2%。这是样本容量增加,均值的标准差减少了误差。
区间估计
点估计是用于估计总体参数的样本统计量,我们不可能通过点估计就给出总体参数的一个精确值,更稳妥的方法是加减一个边际误差,通过一个区间值来估计。
上文的用户调研案例,已经知道了总体均值和标准差。可是它的总体均值也只是通过历次调研作出的假设,并不能反应产品所有用户的评价。一个更实际的应用是,如何通过一次调研来计算用户的总体评价。这是反其道而行之。
通过调研的历史数据,已经知道了用户打分的标准差是1。最近产品人员进行了一次大规模的调研,访问了200位用户,得到样本均值7.5分。现在需要计算总体均值的区间。
通过点估计公式,可以得出样本标准差为0.07。在正态分布的经验公式中,已知任何正态分布的随机变量都有95%的值落在均值附近1.96个标准差以内。因此x拔的值一定有95%落在均值u的1.96个标准差以内。
此时,1.96个标准差等于1.96*0.07 = 0.13。利用总体均值的区间估计公式:
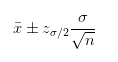
将数据代入:
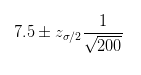
这里多出了一个新的符号Zσ/2,称之为置信水平,之所以除2是因为正态分布左右对称。它代表的是「随机变量都有95%的值落在均值附近1.96个标准差以内」,即均值有95%的概率落在这个区间内,也叫做95%置信水平。推广开来,也有90%置信水平,99%置信水平等。
1.96是95%置信水平的Zσ/2值,我在上文已经求出边际误差为0.13,最后加入平均值得到答案7.36~7.64,于是可以说,通过调研样本均值估计,总体用户的打分有95%的概率在7.36~7.64之间。我们把[7.36,7.64]叫做置信区间。
大家可能也已经猜出来了,为了获得更高的置信水平,必然会得到更宽的置信区间。比如我假设一个置信区间是[7,8],那么它的置信度肯定无限接近100,因为它几乎囊括了所有的可能。如何选择置信水平和区间,是数据分析中的要点之一。
区间估计中还有一种常见情况,即σ未知,上文的案例我们知道了总体的标准差,如果标准差也不知道呢?毕竟案例也只是以历史调研数据假设了标准差,未必反应了用户真实的情况。于是再给出一个新的问题,访问了200位用户,得到样本均值7.5分,标准差为2,那么总体均值是多少?
通过样本标准差估计总体标准差,总体均值是以t分布(上文对应的叫做z分布)的概率分布为依据。t分布假设抽样总体满足正态分布,但是非正态分布中,也是能用t的,效果不错。
t分布依赖一种叫自由度df的的参数。与标准正态分布曲线相比,df越小,t分布曲线愈平坦;df愈大,t分布曲线愈接近正态分布曲线,当df=∞时,t分布曲线为标准正态分布曲线。区间估计公式如下:

公式没有大的变化,总体标准差σ变化为样本标准差s,置信水平由t概率表计算。t概率的区间分布,需要自由度和置信水平两个参数。自由度=样本量-1,案例中的自由度为199。然后使用Excel的TINV( )函数计算,当置信水平为95%时,TINV(0.05,199)=1.97。代入公式:
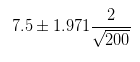
得到区间[7.22,7.77],在总体标准差未知的情况下,可以通过样本均值7.5和标准差2计算总体均值有95%的概率落在7.22~7.77之间。
假设检验
在熟悉掌握点估计和区间估计之后,深入学习假设检验。
何为假设检验?假设检验是对总体参数做一个尝试性的假设,该尝试性的假设称为原假设,然后定义一个和原假设完全对立的假设叫做备选假设。假设检验就是通过样本数据对两个对立假设进行检验。
假设检验有一套成熟的方法论。从参数看,即可以计算平均数,也可以计算比率。从样本看,可以划分为单样本和双样本。单样本是从总体中抽取一部分进行样本均数和总体均数的比较。用户调研就是一个典型的单样本。从假设的条件看,有单侧检验(仅大于或小于的可能性)和双侧(仅不可能,包含大于和小于两种情况)检验。
数据分析中更多的情况是两组样本的比较,譬如男女用户的差异、用户群体的差异、以及产品AB测试的好与坏。因为篇幅原因,案例将重点放在双样本检验中,单样本检验熟悉点估计和区间估计后不难。
回到最开始的案例,当通过调研发现用户对产品评分下降了,接下来得讨论怎么做。产品经理们说:用户都傻兮兮的,它们对产品改版无法作出有效的判断,所以打分不算数,应该用一套更好的判断方法。
这时以产品改版后的活跃相关指标作为标准,其中一半用户不做改变,还是原始功能,成为对照组。另外一半用户体验新功能,为改进组,然后根据一段时间后的表现来判断改版好与不好。
活跃指标怎么设立很大程度影响如何用假设检验。既可以用均值法,即用户平均使用时长,或一段时间窗口内的平均活跃用户数来衡量,也可以用比例法,即某一时间内的活跃率。两者对应不同的公式,这里以平均活跃用户数举例。
假设检验首先需要设立原假设和备选假设,这里很容易犯错。在许多假设检验中,都以备选假设为出现点,它是希望得到支持的结论。因为之前用户调研的评分是下降的,于是检验更希望「拒绝」活跃上升或不变,从而得出下降的结论。
原假设H0:活跃提升或不变;备选假设Ha:活跃下降。如果样本结果得出拒绝H0的结论,那么可以做出Ha为真的推断。
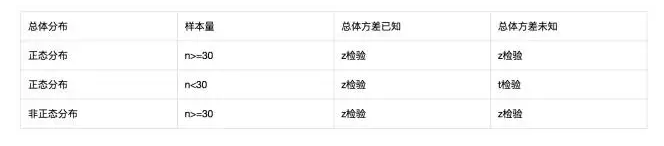
不同的样本量和总体方差使用的检验方法不同,下图是不同情况下使用的检验方法。样本是否大于小于30是因为中心极限定理,在大样本量,且总体方差未知时,使用t检验还是z检验均可,因为t分布近似于z分布。我们使用z检验做双样本均值。
将用户分割出两个群体体验产品功能,原始对照组和改进组都有50000用户。对照组的七日平均活跃数u1=8500,标准差为s1=1250,改进组的七日平均活跃数为u2=8300,标准差s2=1240。当总体标准差未知时,有公式:
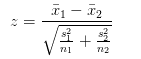
计算出z=25.399,远大于1.96,p值无限接近0,几乎不可能发生,也就说明改进组的活跃上升或者等于是个极小概率事件,我们拒绝了原假设,接受了备选假设。若还想深入的查看活跃究竟下降了多少,使用双样本均值计算置信区间:
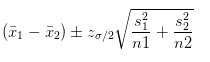
两个样本均值之差的95%置信区间为[183.566,215.433]。也就是说七日平均活跃数有95%的可能性下降了183~215之间。
假设检验的难点在于诸多知识点和业务的结合使用,限于文章的篇幅,我省略了不少概念点,这块需要大家多练习,比如用曾经文章的练习数据,计算上海和杭州的数据分析师工资均值是否相等,金融的工资是不是比电商的高。实际分析中不会有那么复杂的计算,我知道大家公式看晕了,不论Excel、R或者Python都有简便的函数使用,只要知道结果的符号意义就行了。
统计的内容告一段落了,这些都是比较基础的知识点,没有写得过于复杂,其一因为我统计本身不擅长(读书时没好好学),其二应用中我也不追求背后的数学原理。这大概是我写得最吃力的系列了。虽然还有时间序列,方差分析等内容,就留待以后吧。
下一篇文章写业务,因为历史文章已经涉及不少,反复讲没啥意思,所以一篇文章足矣,将数据中涉及的各类业务指标和知识点明即可。然后就是Python了。嗯,基础数据分析的内容已经倒计时了。
相关阅读
数据分析能力养成指南:Excel技巧之甘特图绘制(项目管理)
作者:秦路,微信公众号ID:tracykanc。
本文由 @秦路 原创发布。未经许可,禁止转载。
 等我一分钟 我去找个夸你的句子
等我一分钟 我去找个夸你的句子
 这世上美好的东西不多,牛起来要人命的你就是其一!
这世上美好的东西不多,牛起来要人命的你就是其一!
 不要厉害的这么随意,不然我会觉得我又行了
不要厉害的这么随意,不然我会觉得我又行了
 这就很离谱了,老天爷追着喂饭的主儿~
这就很离谱了,老天爷追着喂饭的主儿~
 我要是有这才华,我走路都得横着走!
我要是有这才华,我走路都得横着走!
 对你的作品崇拜!
对你的作品崇拜!
 反手就是一个推荐,能量满满!
反手就是一个推荐,能量满满!
 感谢分享
感谢分享































