
数据分析能力养成指南20:了解和掌握Python的函数

本文是《如何七周成为数据分析师》的第二十教程,如果想要了解写作初衷,可以先行阅读七周指南。温馨提示:如果您已经熟悉Python,大可不必再看这篇文章,或只挑选部分。
Python之所以灵活,就是因为它函数式编程的特性。今天开始学习Python的一些高级特性。
控制流
Python等程序语言,都是从程序顶端从上到下一行行执行语句,可以把它想象成线性。生活中的很多情况,并不只是单一的线性。
某程序员的老婆叫他上街买几个桃子,吩咐如果有西瓜,买一个。 后来他就真的只买了一个桃子回来。这里就用到了典型的条件判断(程序员有没有买对的吐槽我们先放下),条件是如果有西瓜。
我们用If表示条件:

这是一个最简单的逻辑判断,当我们发现a大于5,输出特定语句。python用缩进控制语法,当if后面的条件为true时,程序才会执行缩进中的内容,否则跳过。缩进在Jupyter中用tab输入,也可以使用四个空格。
当条件为false时,可以用else,此时不会执行if中的内容,而是else。
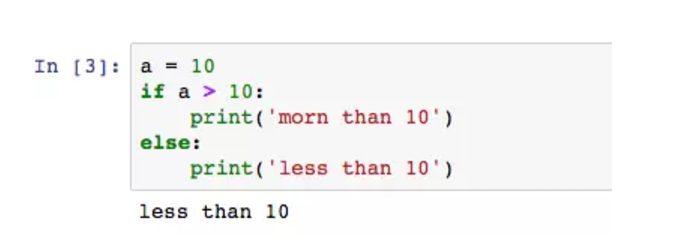
条件可以进一步细化,用elif语句。
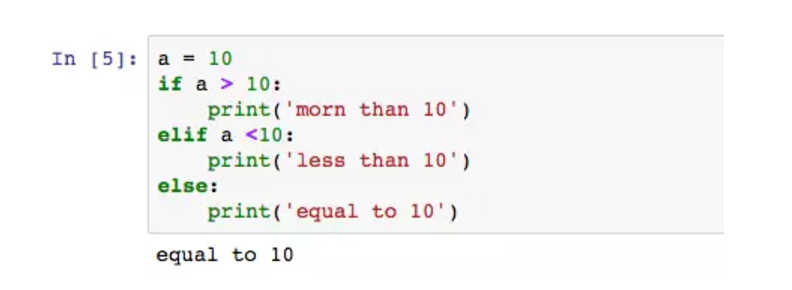
elif可以使用多个。不论if、elif还是else,后面都要加冒号。当if、elif、else中有一个条件执行为true,后续的条件都pass不执行。
我们把程序员买西瓜的故事简单翻译成代码:

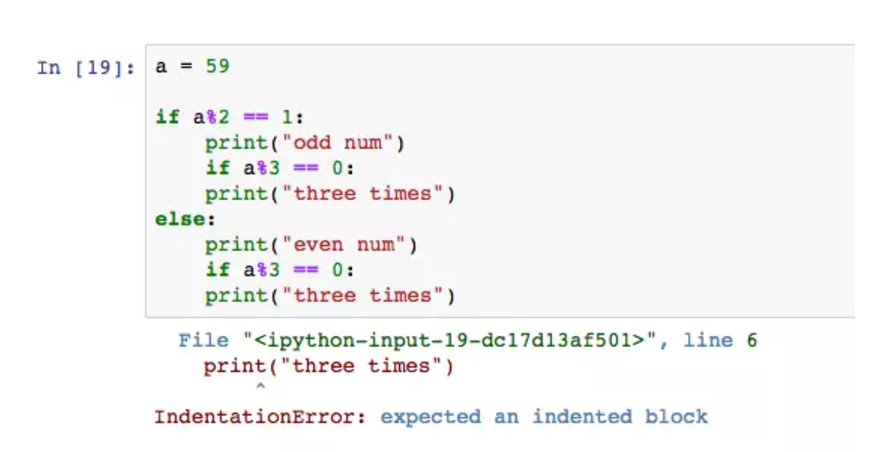
条件判断中可以应对更复杂的逻辑。比如有一个数字,我们即想判断它的奇偶,也想判断它能不能被3整除。

if中套着一个if,我们把它称为嵌套。第二层的if,仍旧要遵循缩进规则,它是基于上第一层的逻辑,所以此时距行首八个空格。如果忽略了缩进,会报错。新手在缩进很容易犯错,尤其是在逻辑复杂有七八个缩进的时候。
while是Python的循环执行语句,在某条件下,一直执行语句,直到条件为False。
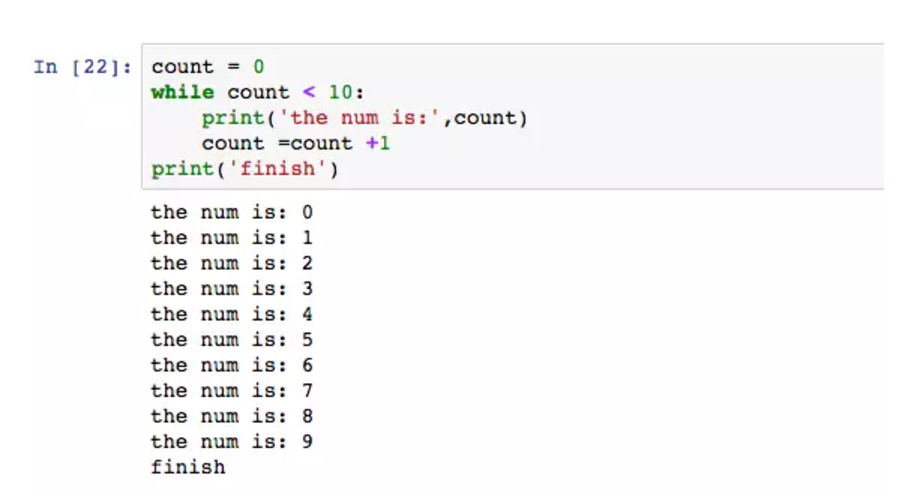
在上图中,count作为计数器,每次循环都会累加1,直到count大于等于10。count=count+1可以有一种更优雅的写法:count += 1。
while还有两个重要的命令,break和continue,break是终止整个循环,continue是跳过本次循环。
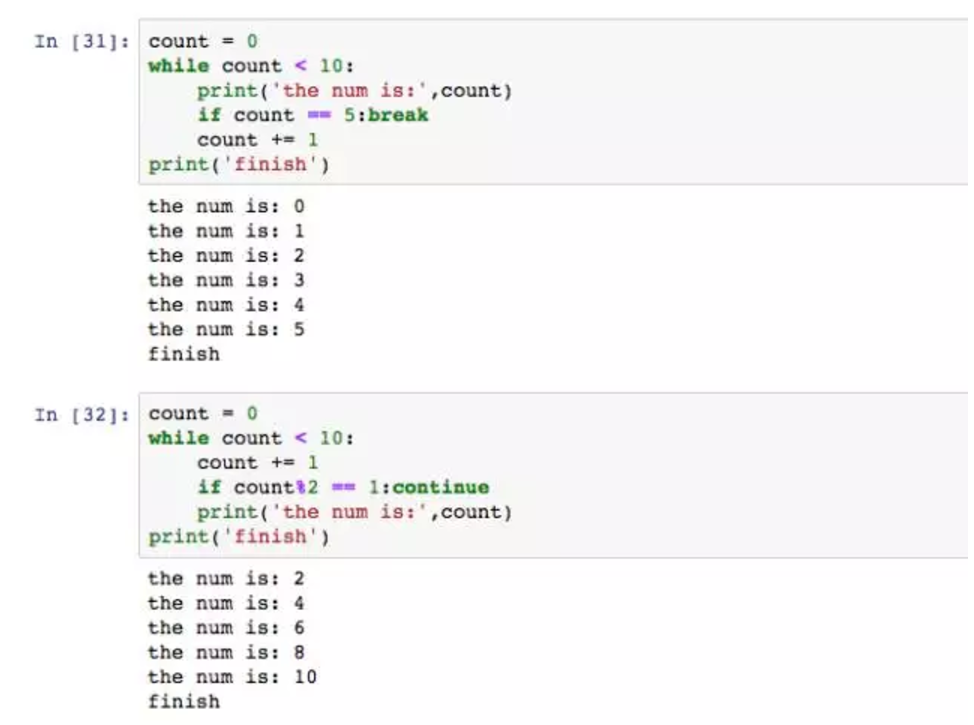
第一个是在循环计数器为5时停止输出,第二个循环是只输出偶数。需要注意的是,如果while的条件始终不为true,那么它为无休止地进行下去,计算机会被拖垮。这也是为什么第二个循环会将count+=1放在上面,因为放在下面会让continue跳过累计计数,永远不会达到10。
和依据条件进行循环的while不同,for语句可以设置循环的次数。
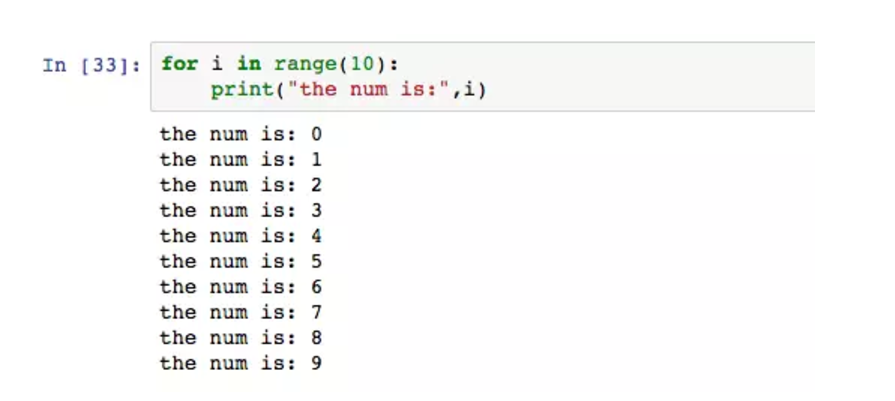
range函数用来控制循环次数,默认从0开始,执行n次。这里的i是循环过程中的数字变量,即第几次循环。如果想设置循环的起始数字,用两个参数表示,第一个为起始,第二个为终止。有一种进阶用法是设置第三个参数n,叫步长,循环过程的计数不是默认的1,而是n,类似于count += n。

for in range 的用法,是循环一组数字。它也能引入更丰富的列表和字典。
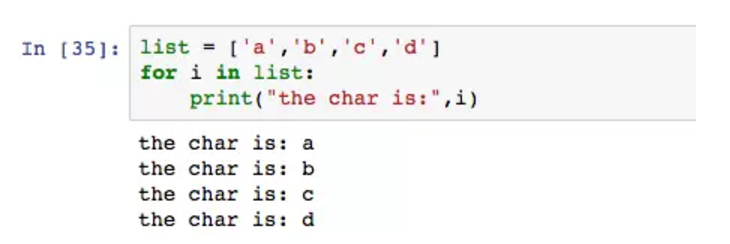
这里for将列表里面的所有元素都遍历出来,i表示list中第几个元素。字典用for比较特殊,因为它是key-value键值对,需要声明循环的目标是key还是value。
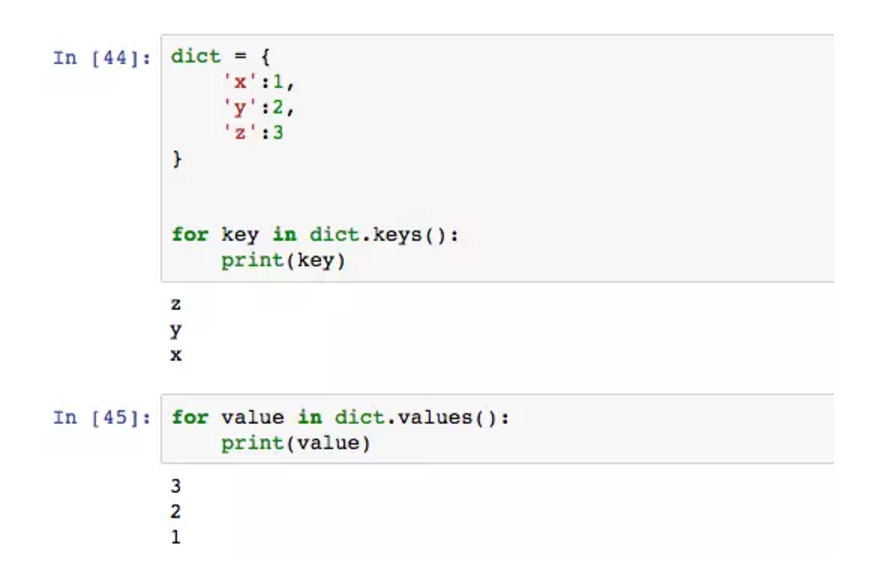
keys()可以不用加,默认的输出就是key。dict的循环输出依旧不是按赋值时的顺序,这点要注意。如果想要同时输出key和value,用items。
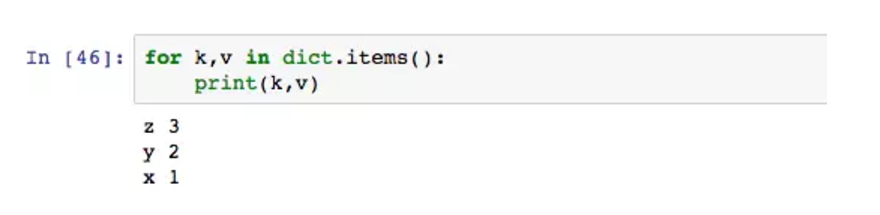
这里的k指代key,v指代value,items将key和value组成元组,把这些元组依旧返回。
严格意义上说,上述的代码可以细分成循环、迭代和遍历。循环是满足一定条件下,执行相同的代码,while就是典型的循环。迭代是按顺序范围访问列表中的项,比如for,上文中针对列表和字典的循环更应该称呼为迭代。遍历是按一定的规则访问所有的元素,它可以是线性,也可以是树型。另外还有一种用法叫递归,它在函数中用到。
函数
大家在读书时想必都学过函数,y=f(x)就是一个典型的函数,通过输入x,经过特定的函数,最终输出我们想要的结果y。
在计算机语言中,函数可以简单地抽象为输入和输出。很多时候,我们并不需要知道输入和输出的底层计算过程,只需要知道这个函数能输出什么。这点和Excel中的函数很像。
Python有很多内置的函数,abs、len、int、max等,具体的应用可以查询文档。对于新手,不需要掌握全部的函数,花费的精力太久,最好的方法是学会查询。这一点通过搜索引擎加关键词轻松做到。
当内置函数无法满足我们的需求时,就需要用到自定义函数。
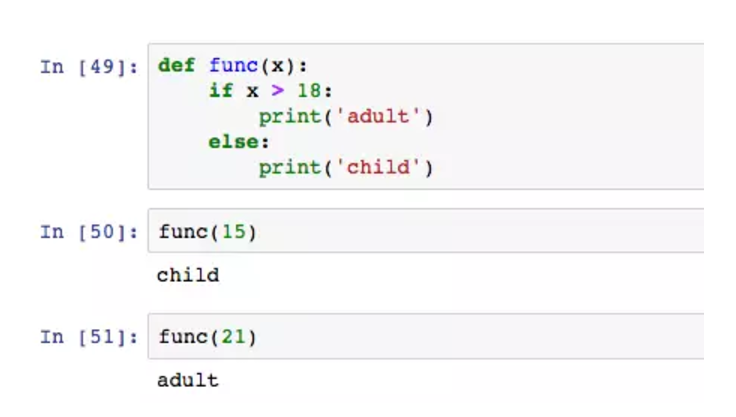
通过def定义函数,func是函数的名称,括号中是函数的参数,也可以理解为输入。冒号依旧是必须的。缩进块内是函数的主体,没有被缩进的部分不会被认为是函数。
案例中的代码是一个简单的判断器,输入年龄x,在函数主体中进行判断,分别输出adult或者child。当我们定义好函数,在后续的使用中直接调用函数,并且输入,不用再一遍遍的写重复代码。
函数的意义就是将工作中的重复内容简化,一个良好的程序员会定义清晰简洁的函数。对于数据分析师,虽然函数的要求不那么严格,但是学会了也能将数据工作精简。
比如你每天都需要重复相同的数据清洗工作,诸如拼接,计算,合并等,把繁琐的工作步骤写成一个函数,正式名字叫封装,以后的工作只需要运行函数就能轻松搞定。
函数可以定义多个参数/输入,也能将运行后的结果输出。
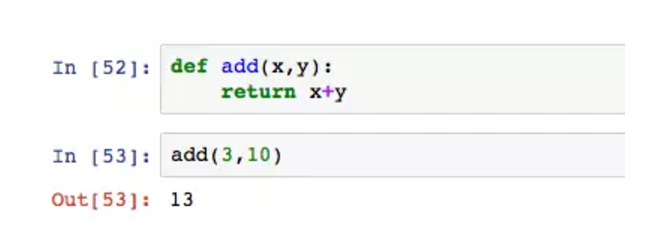
上面就是一个最简单的加法函数,return表示将结果返回。返回的结果可以用于赋值,result = add(3,10),result就是13。参数除了输入的作用,本身还能作为开关。
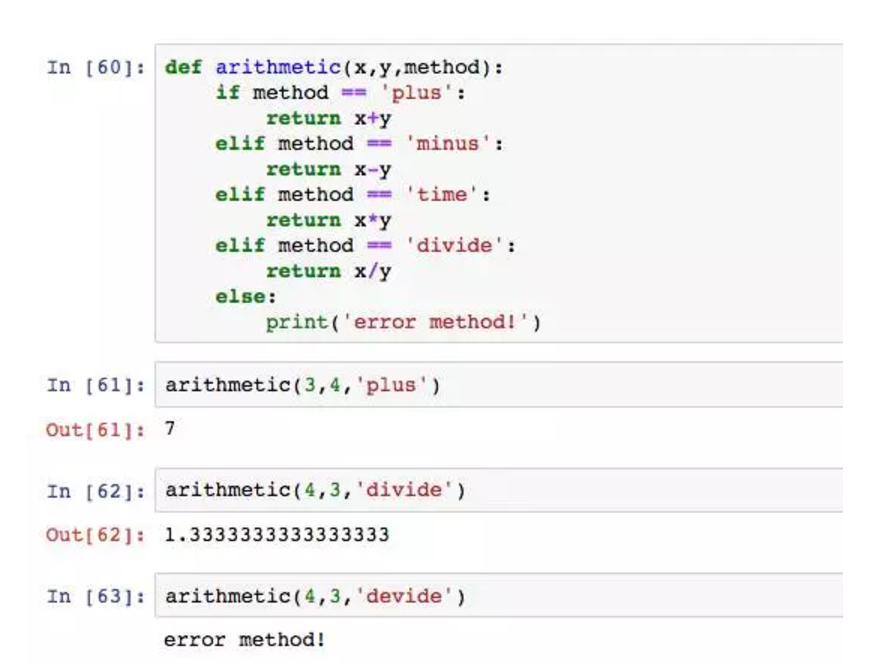
案例是一个简单的四则运算器,第三个参数就是开关,选择加减乘除。这点,不妨想一下excel的函数比如vlookup,它的第四个参数true和false就是判断要精确匹配还是模糊匹配,是一个开关的作用。

如果足够细心,你会发现vlookup的第四个参数可以忽略,因为它默认为True,在使用的过程中实际有三个就行了,方便使用。Python也能设置默认参数。
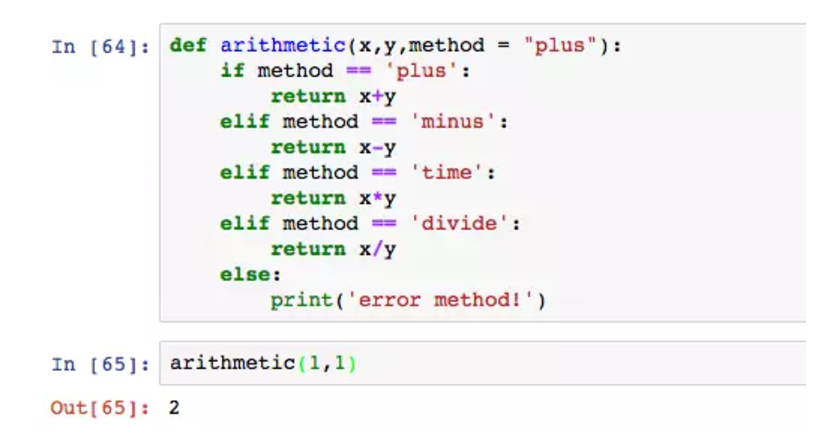
只要在参数部分自动赋值,就可以作为默认参数,这里默认执行plus,不需要额外声明。
函数能够进行复杂运算吗?答案是肯定的,我们结合描述统计,通过输入一组数据,返回描述统计中的常用指标,最大值,最小值,中位值,平均值。
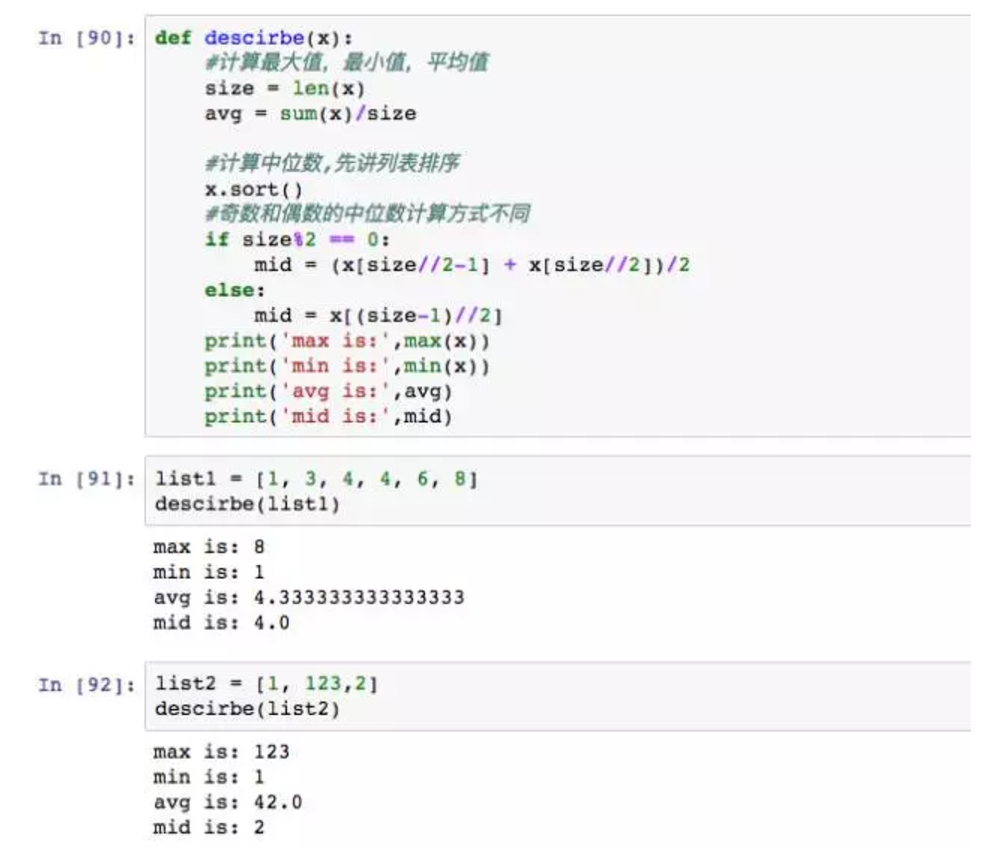
最大值、最小值和平均数的计算没有难度,中位数复杂一些,奇数和偶数的计算逻辑不一样,所以函数中要用到if判断。大家可以思考一下为什么要排序,以及除法为什么是//而不是/,这些都是早期知识点的掌握。还可以再想一下,这个函数会不会有问题?
接下来继续加大难度,如果是输入一个数组,求其标准差,应该怎么计算?
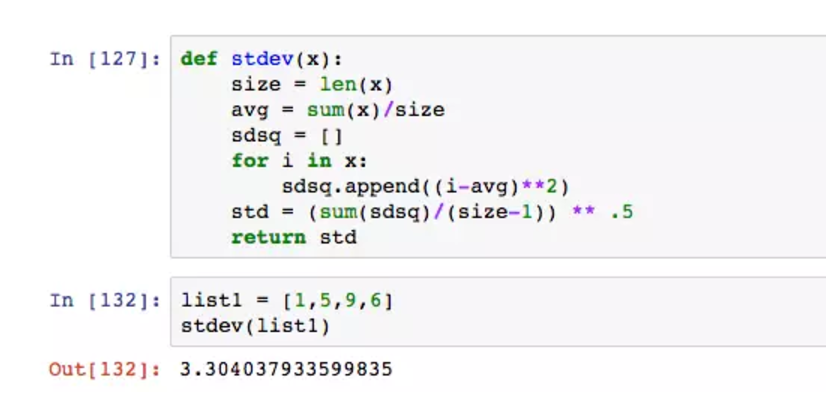
在计算标准差的过程中,我们要先定义一个空列表,循环求出(实际值-平均数)^2的值,求和后再除以变异值,整个步骤略显冗余。在Python中,步骤可以再精简。
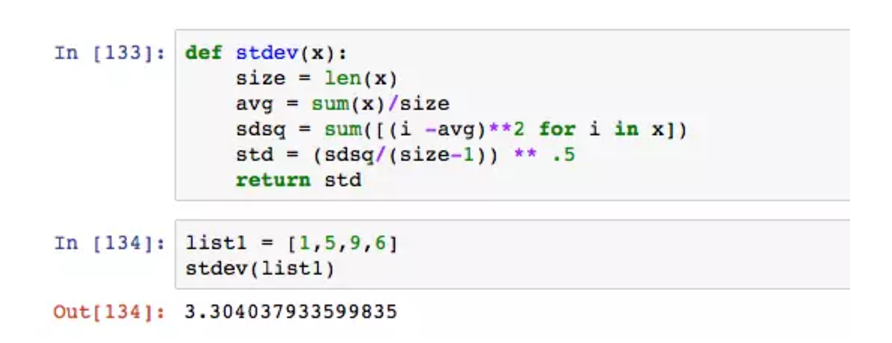
[(i-avg)**2 for i in x]是一种优雅写法,它直接将循环计算后的结果生成一个新列表,避免使用append,也不需要缩进。接下来看几个简化的应用。
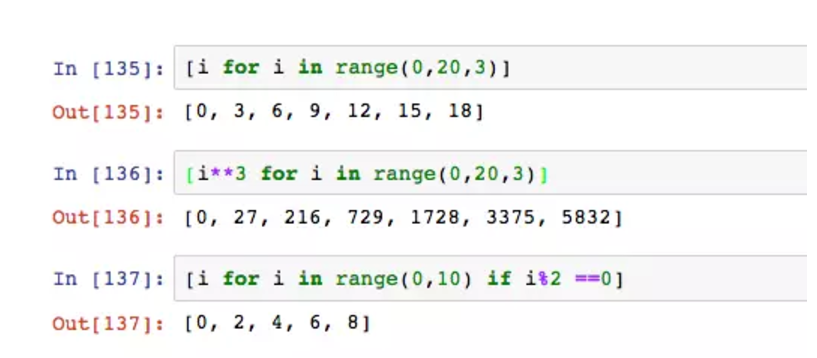
在完成标准差函数后,如果我们希望同时生成标准差和方差应该如何处理?函数可以有多个输入,那么自然也支持多个输出。
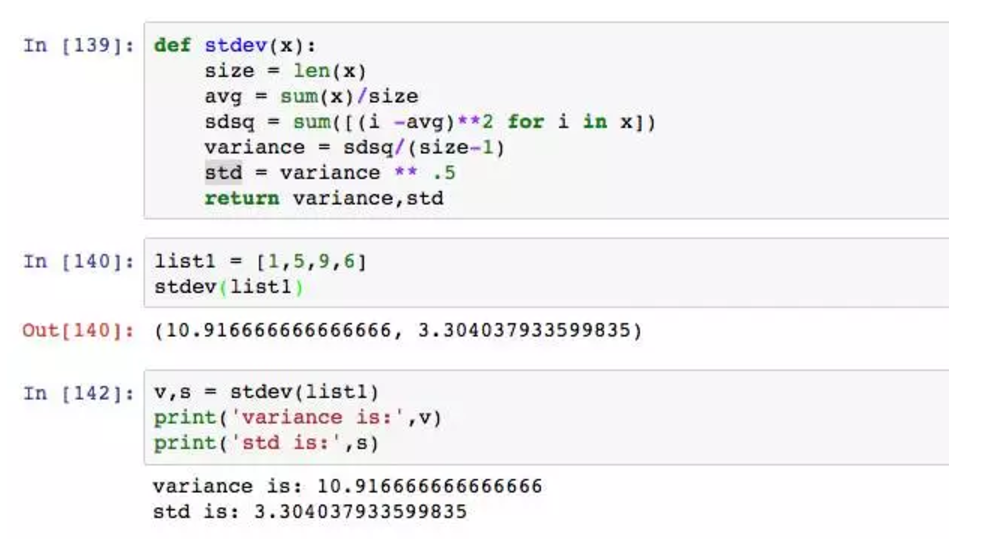
return多个值时,它返回的是元组,也可以将元组赋值给多个变量。
在函数中,还有更多的用法,比如可变参数,关键字参数,递归函数等。不过数据分析师用不太到,很多业务分析是一次性的,代码写得丑就丑了,用拼音命名变量也可以,毕竟和excel比起来,效率提升还是足够的。
包、模块和类
学会函数,工作中让你省一半力气,但是Python的优势就是还能再省力。比如中位数、标准差等,依旧需要写代码,有没有现成的直接调用呢?
第一种思路是搜索,「python 中位数」和「python 标准差」的关键词在网上可以搜出一堆,直接参考即可。
第二种思路是调包,世界上好心人很多,他们已经写好了现成的诸多功能,把它们共享在了网上,这些功能统一做成了「包」。
包的概念类似于文件夹,文件夹中放着很多文件,文件在Python中指代「模块」,对应一个.py文件。py文件中包含着具体的代码,代码太多会显得比较凌乱,为了规范和整理代码,引入了「类」。类是一种抽象的概念,是面向对象编程的核心,数据分析不用深入理解这块,只要知道类是各种函数的集合,方便复用,用起来很简单就行。
拿之前的统计函数举例,程序员老王是一个好人,它将统计的常用代码做成了一个包叫「老王统计包」,老王统计包里面有多个模块,比如描述统计模块,概率模块。描述统计模块中有一个stats类,把计算平均数标准差的函数都装进去了。

上述代码就是一个简化的类,list是根据Stats创建的实例,实例是编程名词,粗糙理解就是把具体的数据存到内存空间了。然后我们直接为list调用不同的函数,不论sum、count还是avg,一次性出来。数据分析师不用专程学怎么创建类,大概了解就行。
接下来的问题是,怎么使用这些包、模块和类呢?
Python提供了很方便的操作命令,pip install。以往后我们要学的pandas为例。打开终端/cmd,键入pip install pandas。如果系统里既安装python2又安装python3,则键入pip3 install pandas。
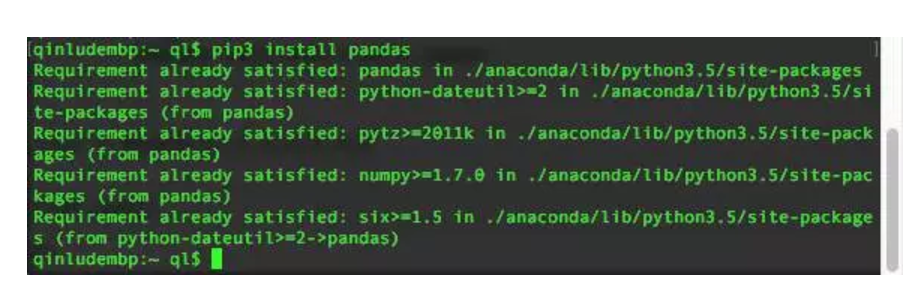
如果未安装过,会自动安装,已经安装过的会提醒已安装。我们用的Anaconda3已经集合了绝大部分的数据分析包,不需要安装了。Anaconda3有另外一个命令可以安装,是conda install,如果Python3.3,Python3.4,Python3.5安装了一堆版本,这个命令可以切换版本方便点。
安装包很容易遇到各种各样的问题,windows会比较多,遇到的话擅用搜索引擎即可。
包安装好以后就可以使用了,在Python用import表示加载包,也可以加载Python自带的模块。默认放在文件开头。
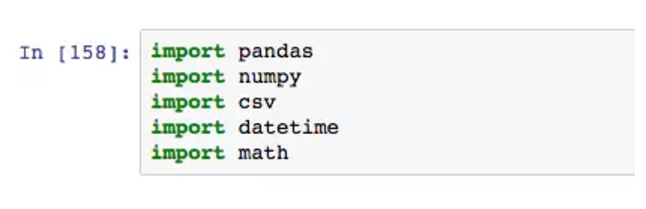
Python提供了非常丰富的包和模块,合理应用这些模块将极大程度的提供数据分析能力。numpy、scipy、pandas是数据分析最常用的三个包,matplotlib、seaborn是常用的绘图包,scikit-learn、Gensim、NLTK是机器学习相关的包,urllib、BeautifulSoup是常用的爬虫包等。
在下一篇内容,会讲解用Pandas进行数据分析。当然中间会穿插一到两篇强化基础的内容,比如做Python的算法竞赛题、高阶函数如Map/Reduce和filter的使用、实现数据清洗等。
相关阅读
数据分析能力养成指南:Excel技巧之甘特图绘制(项目管理)
作者:秦路,微信公众号ID:tracykanc。
本文由 @秦路 原创发布。未经许可,禁止转载。
 等我一分钟 我去找个夸你的句子
等我一分钟 我去找个夸你的句子
 这世上美好的东西不多,牛起来要人命的你就是其一!
这世上美好的东西不多,牛起来要人命的你就是其一!
 不要厉害的这么随意,不然我会觉得我又行了
不要厉害的这么随意,不然我会觉得我又行了
 这就很离谱了,老天爷追着喂饭的主儿~
这就很离谱了,老天爷追着喂饭的主儿~
 我要是有这才华,我走路都得横着走!
我要是有这才华,我走路都得横着走!
 对你的作品崇拜!
对你的作品崇拜!
 反手就是一个推荐,能量满满!
反手就是一个推荐,能量满满!
 感谢分享
感谢分享































